Nunca digas nunca… pero creo que esta ha sido mi última participación como ponente en una WordCamp. Han sido cuatro años, donde he tenido la suerte y el honor de que me escogieran en todas las WordCamps en las que he aplicado.
Por ello no puedo estar más que agradecido a los organizadores de Bilbao 16, Sevilla 16, Santander 16, Madrid 17, Santander 17, Zaragoza 18, Barcelona 18, Granada 18, Madrid 19 y Sevilla 19.
Sin más, en esta última de Sevilla, ha sido un taller sobre expresiones regulares. El taller constaba de una primera parte de teoría y una segunda de ejercicios prácticos para poner en uso lo aprendido.
¿Qué son las expresiones regulares?
Las expresiones regulares son patrones utilizados para encontrar una determinada combinación de caracteres dentro de una cadena de texto.
- No se consideran lenguaje de programación
- Son utilizadas para buscar patrones, realizar operaciones de sustitución, validaciones, etc…
- Se utilizan en HTML5, JavaScript, PHP… con pequeñas diferencias entre ellos
- Se leen siempre de izquierda a derecha
Algunos desarrolladores cuando se enfrentan a un problema piensan que la solución es usar expresiones regulares. En este momento, ya tienen dos problemas.
Jamie Zawinski
Caracteres y Metacaracteres
- ^ Inicio de regex
- $ Fin de regex
- * Coincide con lo anterior cero o más veces
- + Coincide con lo anterior una o más veces
- ? Coincide con lo anterior cero o una vez
- – Definir un rango (A-Z)
- { } Repetición
- ( ) Agrupamiento
- [ ] Un carácter o rango de caracteres
- . Cualquier carácter, excepto salto de línea
- \ Escape
- | Elementos alternos
- ! Negación
El metacaracter comodín
El punto «.» es el comodín, representa cualquier carácter excepto el salto de línea. De este modo:
De este modo, una expresión regular como esta /.a.a.a/ coincidirá con palabras como: mañana, banana, papaya, fabada…
¿Cómo se leería esta expresión regular? Cualquier palabra que contenga cualquier carácter seguido de una «a», seguido de cualquier carácter, seguido de otra «a», seguido otra vez de cualquier carácter y seguido de nuevo por otra «a».
Caracteres especiales
Son los siguientes:
- \t Tabulador
- \v Tabulador vertical
- \r Retornos de carro
- \n Nueva línea
- \e Escape
- \0 Null
Conjunto de caracteres
Definiremos un conjunto de caracteres por medio de corchetes [ ]. Se evaluarán los caracteres dentro del conjunto de manera individual, NO palabras completas. No importa el orden de los caracteres dentro del conjunto.
- /[aeiou]/ Buscará uno de los caracteres incluídos dentro del conjunto, en este caso cualquier vocal.
- /[áéíóú]/ Buscará uno de los caracteres incluídos dentro del conjunto, en este caso cualquier vocal acentuada.
Da igual el orden, si buscamos /c[ao]sa/ ó /c[oa]sa/ nos coincidirá tanto con «casa» como con «cosa».
Rango de caracteres
Logramos especificar mediante corchetes y guiones medios un rango de caracteres. Aquí si es importante el orden unicode, es decir, podremos especificar un rango de caracteres comprendido entre la A y la Z, pero nunca entre la Z y la A.
- /[a-z]/ De la «a» a la «z», en minúsculas, alfabeto inglés, sin acentos ni “ñ”
- /[A-Z]/ De la «A» a la «Z», en mayúsculas, alfabeto inglés, sin acentos ni “Ñ”
- /[0-9]/ Dígitos entre el «0» y el «9»
- /[a-zA-z0-9]/ Podemos definir varios rangos de caracteres dentro de un conjunto
- /[á-ü]/ Todas las vocales acentuadas (acentos, circunflejos, diéresis, etc…) en minúsculas
También podemos especificar una negación o conjunto negativo de caracteres. Es decir, que no encuentre un conjunto de caracteres definido. Para ello utilizaremos el carácter ^ dentro de los corchetes.
- /[^aeiou]/ Encontrará cualquier caracter excepto las vocales
- /[^«#$%&/()=*]/ Encontrará cualquier caracter excepto los definido entre corchetes
Los metacaracteres dentro de los conjuntos de caracteres ya están «escapados», excepto los siguientes:
- ] – ^ /
- /var[[(][0-9][])]/ var(9) ó var[9]
Abreviaciones de conjuntos de caracteres
Existen abreviaciones para definir conjuntos de caracteres:
- \d Dígitos. Equivale a [0-9]
- \w Caracteres. Equivale a [a-zA-Z0-9_]
- \s Whitespaces. Equivale a [ \t\r\n]
- \D No dígito. Equivale a [^0-9]
- \W No caracteres. Equivale a [^a-zA-Z0-9_]
- \S No whitespaces [^ \t\r\n]
Flags
Se pueden especificar una serie de flags al final de la expresión para acotar el ámbito de búsqueda dentro de un texto de entrada:
- /regex/
- /regex/g global. No se detiene ante la primera coincidencia
- /regex/i insensitive. Busca en mayúsculas y minúsculas
- /regex/m multiline. Los metacaracteres ^ y $ aplican a cada línea, no a toda la cadena
- /regex/s single line. El metacaracter . coincidirá con saltos de línea
- /regex/gms Pueden combinarse varios modificadores o flags al mismo tiempo
Metacaracteres de repetición
Los metacaracteres de repetición dentro de las expresiones regulares nos permiten definir patrones de repetición de los caracteres precedentes. Son los siguientes:
- * Cero o más veces el elemento precedente
- + Una o más veces el elemento precedente
- ? Cero o una vez el elemento precedente
Veamos en el siguiente ejemplo cómo se comportarían si los ponemos detrás de una «s»:
- /as*/ a, as, asss
- /as+/ a, as, asss
- /as?/ a, as, asss
Cuantificadores de repetición
También podemos especificar una repetición de caracteres determinada, definida entre mínimos y máximos del siguiente modo:
- {num} Num veces el elemento precedente
- {min,max} Elemento precedente entre min – max
- {min,} Elemento precedente min veces
Veamos en el siguiente ejemplo cómo se comportaría ante la búsqueda de un número determinado de dígitos:
- /\d{4}/ 4 dígitos exactamente
- /\d{4,8}/ Entre 4 y 8 dígitos, ambos inclusive
- /\d{4,}/ Mínimo 4 dígitos
Expresiones regulares Greedy vs Lazy
Las expresiones regulares son greedy (codiciosas) por defecto. Siempre van a intentar seleccionar la cadena más grande. Ejemplo:
- /<p>(.*)<\/p>/ Intentará seleccionar todo los caracteres (.*) entre la primera y última etiqueta de párrafo que encuentre
En un texto con dos párrafos, el matcheo será sobre todo el texto: (<p>lorem ipsum<\/p><p>sit amet<\/p>)
Se convertirán en lazy (perezosas) añadiendo una ? a nuestra expresión regular
- /<p>(.*?)<\/p>/ Intentará seleccionar todo los caracteres (.*) entre la primera etiqueta de inicio de párrafo y la primera etiqueta de cierre de párrafo que encuentre
De este modo, se seleccionará el primer cierre de párrafo que encuentre: (<p>lorem ipsum<\/p>)(<p>sit amet<\/p>)
| Greedy | Lazy |
| (.*) | (.*?) |
| (.+) | (.+?) |
| (.?) | (.??) |
| {min.max} | {min,max}? |
Metacaracteres para agrupar
Por medio de los paréntesis () podemos agrupar expresiones regulares. Y además podremos:
- Aplicar operadores de repetición a grupos
- Hacer las expresiones más legibles
- Capturar un grupo para matchear o reemplazar
- No es posible agrupar dentro de un conjunto de caracteres [()]
Metacaracteres para alternar
Por medio del metacaracter | (pipe) podemos alternar expresiones regulares. Equivale al OR lógico. Se leen de izquierda a derecha y tienen prioridad del mismo modo, primero las de la izquierda.
- /<(p|div)>/
Hay que tener en cuenta que las expresiones regulares son eager (ansiosas).
- /(moto|motocicleta)/ moto y motocicleta
- /moto(cicleta)?/ moto y motocicleta
Trabajando con grupos
Las expresiones agrupadas entre paréntesis () por defecto son “capturadas”. Podemos referenciar los grupos del \1 al \9.
- /<(div|p)>.*<\/(\1)>/
Al referenciar con \1, buscará la misma coincidencia que la capturado en el grupo 1, en nuestro ejemplo un div o un párrafo
- ✔ <div>Hola mundo</div>
- ✔ <p>Hola mundo</p>
- ? <div>Hola mundo</p>
Si lo deseamos, podemos no capturar un grupo anteponiendo ?: En este ejemplo capturaríamos una URL completa:
- /(http|https):\/\/([^\/\r\n]+)(\/[^\r\n]*)?/
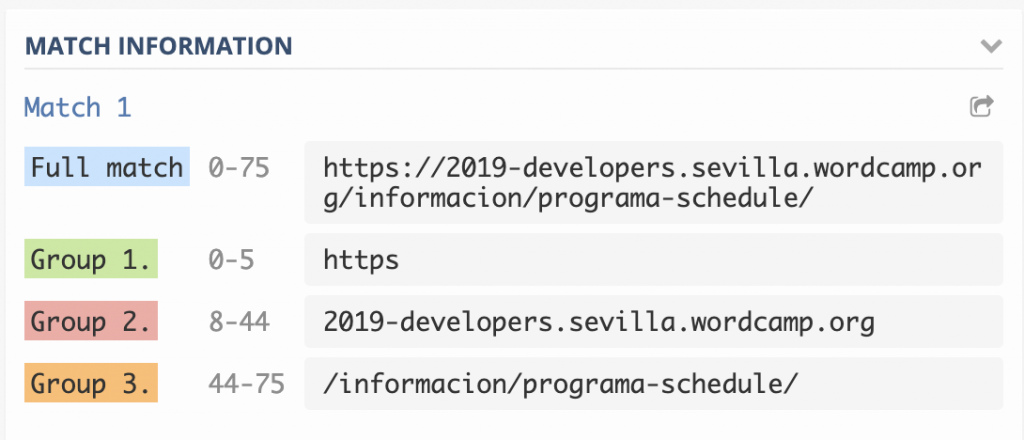
Como vemos en este ejemplo, estamos capturando 3 grupos: el protocolo, el dominio y la ruta. Si quisiéramos simplemente capturar la ruta, la expresión regular quedaría del siguiente modo:
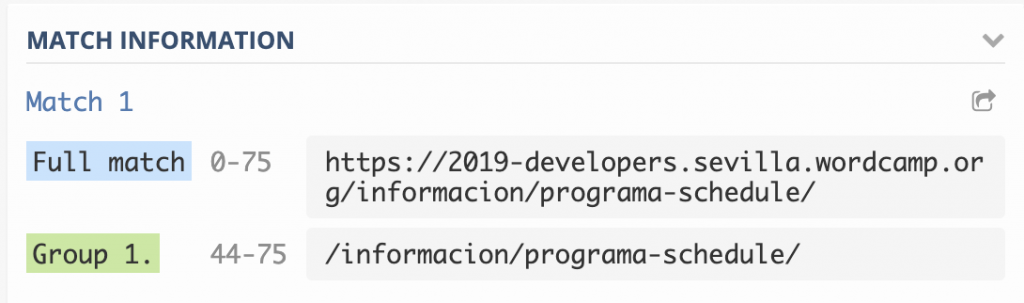
- /(?:http|https):\/\/(?:[^\/\r\n]+)(\/[^\r\n]*)?/
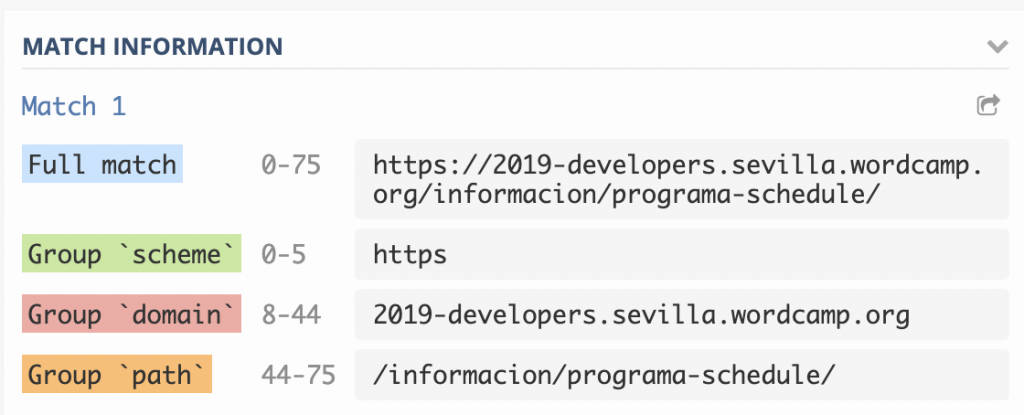
Por último, y además muy útil, podemos nombrar los grupos de captura, con el fin de obtener los resultados de la expresión regular de una manera más legible. Obtendremos una clave en lugar de un número en el array de resultados mediante (?<name>…), (?’name’…) o (?P<name>…).
- /(?<scheme>.*):\/\/(?<domain>[^\/\r\n]+)(?<path>\/[^\r\n]*)?/
Aserciones
En las expresiones regulares hay 4 tipos de aserciones: Positive Lookahead, Negative Lookahead, Positive Lookbehind y Negative LookBehind. Vamos a ver cada una de ellas:
Positive Lookahead
Futuro positivo. Sólo matchea si encuentra una condición futura, es decir: si termina en… La condición no es capturada.
- /guarda(?=barros|bosques)/
- ✔ guardabarros
- ✔ guardabosques
- ? guardaespaldas
Negative Lookahead
Futuro negativo. Sólo matchea si no encuentra una condición futura, es decir: si no termina en… La condición no es capturada.
- /guarda(?!barros|bosques)/
- ? guardabarros
- ? guardabosques
- ✔ guardaespaldas
Positive Lookbehind
Pasado positivo. Sólo matchea si encuentra una condición pasada, es decir: Si comienza por… La condición no es capturada.
- /(?<=solu|informa)ción/
- ✔ Tengo la información
- ✔ con la solución
- ? de la ecuación
Negative Lookbehind
Pasado negativo. Sólo matchea si no encuentra una condición pasada, es decir: Si no comienza por… La condición no es capturada.
- /(?<!solu|informa)ción/
- ? Tengo la información
- ? con la solución
- ✔ de la ecuación
Condicionales if-then-else
Podemos hacer un if-then-else en expresiones regulares. Si if se evalúa como true, se intentará matchear con then, en caso contrario con else. Veámoslo con un ejemplo:
- /(This condition)?(?(1) is true| is false)/
- This condition is true
- This other one is false
Buscamos el grupo (This condition)? cero o una vez debido a la interrogación. A continuación, nuestra condición se agrupa entre paréntesis. El if es el ?(1), que hace referencia al grupo 1, y el then y el else, se separan mediante un pipe. Esto último no se captura.
Expresiones regulares legibles
En ocasiones nos encontramos con un chorizo de expresión regular en un método sin comentar.
- /(?:(?=.{17}$)97[89][ -](?:[0-9]+[ -]){2}[0-9]+[ -][0-9]|97[89][0-9]{10}|(?=.{13}$)(?:[0-9]+[ -]){2}[0-9]+[ -][0-9Xx]|[0-9]{9}[0-9Xx])/
Una herencia de alguien que ya no trabaja aquí, o de nuestro yo de hace un tiempo. Tratar de averiguar lo que hace puede ser la muerte a pellizcos. En este caso corresponde a una expresión regular para obtener un ISBN.
Por eso es siempre muy recomendable comentar cada grupo o sección de nuestra expresión regular:
- /^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?!.*\s).*$/
"/^" . //Inicio de regex
"(?=.*\d)" . //Si existe al menos un número
"(?=.*[a-z])" . //Si existe al menos una minúscula
"(?=.*[A-Z])" . //Si existe al menos una mayúscula
"(?!.*\s)" . //Que no existan espacios
".*" . //Todo, cero o más veces
"$/" //Fin de regexTambién existe una librería en PHP para construir expresiones regulares. La tienes en GitHub y puedes construir expresiones regulares de esta manera:
<?php
$regex = new VerbalExpressions();
$regex->startOfLine()
->then("http")
->maybe("s")
->then("://")
->maybe("www.")
->anythingBut(" ")
->endOfLine();Expresiones regulares en WordPress
Disponemos de algunas funciones auxiliares. Como por ejemplo get_shortcode_regex(). Devuelve la expresión regular utilizada para buscar shortcodes dentro de un contenido. Combina todas las etiquetas de shortcodes registrados en una sola expresión regular.
También disponemos de la función wp_spaces_regexp(). Devuelve la expresión regular para caracteres de espacios en blanco comunes: espacios, nuevas líneas, tabs,   y el nbsp UTF-8. Evita posibles errores en la codificación de un espacio.
<?php
$spaces = wp_spaces_regexp();
$pattern =
'/<p>' // Opening paragraph
. '(?:' . $spaces . ')*+' // Optional leading whitespace
. '(.*)' // The regex
. '(?:' . $spaces . ')*+' // Optional trailing whitespace
. '<\\/p>/'; // Closing paragraphHasta aquí el taller de expresiones regulares de WordCamp Sevilla 2019. Puedes ver la presentación desde aquí, y actualizaré el post cuando salga el vídeo en wordpress.tv.
Puede que también te interese